Asymptotic Equipartition Property
We have been looking at the problem of data compression, algorithms for the same as well as fundamental limits on the compression rate. In this chapter we will approach the problem of data compression in a very different way. The basic idea of asymptotic equipartition property is to consider the space of all possible sequences produced by a stochastic (random) source, and focusing attention on the "typical" ones. The theory is asymptotic in the sense that many of the results focus on the regime of large source sequences. This technique allows us to recover many of the results for compression but in a non-constructive manner. Beyond compression, the same concept has allowed researchers to obtain powerful achievability and impossibility results even before a practical algorithm was developed. Our presentation here will focus on the main concepts, and present the mathematical intuition behind the results. We refer the reader to Chapter 3 in Cover and Thomas and to Information Theory lecture notes (available here) for some details and proofs.
Before we get started, we define the notation used throughout this chapter:
- Alphabet: specifies the possible values that the random variable of interest can take.
- iid source: An independent and identically distributed (iid) source produces a sequence of random variables that are independent of each other and have the same distribution, e.g. a sequence of tosses of a coin. We use notation for iid random variables from distribution .
- Source sequence: denotes the -tuple representing source symbols, and represents the set of all possible . Note that we use lowercase for a particular realization of .
- Probability: Under the iid source model, we simply have where we slightly abuse the notation by using to represent both the probability function of the -tuple and that for a given symbol .
As an example, we could have alphabet and a source distributed iid according to . Then the source sequence has probability .
Before we start the discussion of asymptotic equipartition property and typical sequences, let us recall the (weak) law of large numbers (LLN) that says the empirical average of a sequence of random variables converges towards their expectation (to understand the different types of convergence of random variables and the strong LLN, please refer to a probability textbook).
That is for arbitarily small , as becomes large, the probability that the empirical average is within of the expectation is .
With this background, we are ready to jump in!
The -typical set
Recall that is the entropy of the random variable . It is easy to see that the condition is equivalent to saying that . The set of all **-typical** sequences is called the **-typical set** denoted as . Put in words, the **-typical set** contains all -length sequences whose probability is close to .Next, we look at some probabilities of the typical set:
For any ,
- .
- For large enough ,
Simply put, this is saying that for large , the typical set has probability close to and size roughly
Proof sketch for Theorem-2
- This follows directly from the Weak LLN by noting the definition of typical sequences and the following facts: (i) (since this is iid). (ii) from the definition of entropy. Thus applying the LLN on instead of directly gives the desired result.
Both 2 & 3 follow from the definition of typical sequences (which roughly says the probability of each typical sequence is close to ) and the fact that the typical set has probability close to (less than just because total probability is atmost and close to due to property 1).
Intuition into the typical set
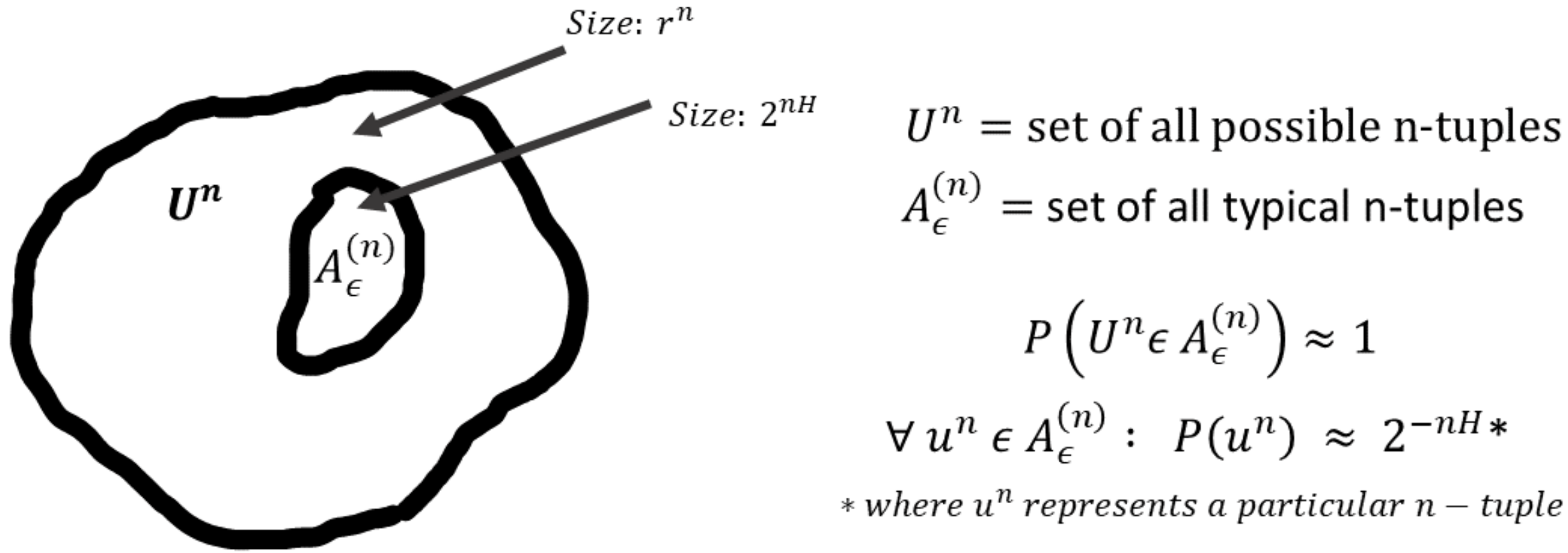
To gain intuition into the typical set and its properties, let and consider the set of all length sequences with size . Then the AEP says that (for sufficiently large), all the probability mass is concentrated in an exponentially smaller subset of size . That is,
Furthermore, all the elements in the typical set are roughly equiprobable, each with probability . Thus, contains within itself a subset that contains almost the entire probability mass, and within the subset the elements are roughly uniformly distributed. It is important to note that these properties hold only for large enough since ultimately these are derived from the law of large numbers. The intuition into typical sets is illustrated in the figure below.
What does the elements of the typical set look like?
- Consider a binary source with . What is the size of the typical set (Hint: this doesn't depend on !)? Which elements of are typical? After looking at this example, can you still claim the typical set is exponentially smaller than the set of all sequences in all cases?
- Now consider a binary source with . Recalling the fact that typical elements have probability around , what can you say about the elements of the typical set? (Hint: what fraction of zeros and ones would you expect a typical sequence to have? Check if your intuition matches with the expression.)
- In part 2, you can easily verify that the most probable sequence is the sequence consisting of all s. Is that sequence typical (for small )? If not, how do you square that off with the fact that the typical set contains almost all of the probability mass?
Before we discuss the ramifications of the above for compressibility of sequences, we introduce one further property of subsets of . This property says that any set substantially smaller than the typical set has negligible probability mass. Intuitively this holds because all elements in the typical set have roughly the same probability, and hence removing a large fraction of them leaves very little probability mass remaining. In other words, very roughly the property says that the typical set is the smallest set containing most of the probability. This property will be very useful below when we link typical sets to compression. Here we just state the theorem and leave the proof to the references.
Compression based on typical sets
Suppose you were tasked with developing a compressor for a source with possible values, each of them equally likely to occur. It is easy to verify that a simple fixed-length code that encodes each of the value with bits is optimal for this source. But, if you think about the AEP property above, as grows, almost all the probability in the set of -length sequences over alphabet is contained in the typical set with roughly elements (where ). And the elements within the typical set are (roughly) equally likely to occur. Ignoring the non-typical elements for a moment, we can encode the typical elements with bits using the simple logic mentioned earlier. We have encoded input symbols with bits, effectively using bits/symbol! This was not truly lossless because we fail to represent the non-typical sequences. But this can be considered near-lossless since the non-typical sequences have probability close to , and hence this code is lossless for a given input with very high probability. Note that we ignored the 's and 's in the treatment above, but that shouldn't take away from the main conclusions that become truer and truer as grows.
On the flip side, suppose we wanted to encode the elements in with bits for some . Now, bits can represent elements. But according to theorem 2 above, the set of elements correctly represented by such a code has negligible probability as grows. This means a fixed-length code using less than bits per symbol is unable to losslessly represent an input sequence with very high probability. Thus, using AEP we can prove the fact that any fixed-length near-lossless compression scheme must use at least bits per symbol.
Lossless compression scheme
Let us now develop a lossless compression algorithm based on the AEP, this time being very precise. As before, we focus on encoding sequences of length . Note that a lossless compression algorithm aiming to achieve entropy must be variable length (unless the source itself is uniformly distributed). And the AEP teaches us that elements in the typical set should ideally be represented using bits. With this in mind, consider the following scheme:
Fix , and assign index ranging from to the elements in (the order doesn't matter). In addition, define a fixed length code for that uses bits to encode any input sequence. Now the encoding of is simply:
- if , encode as followed by
- else, encode as followed by
Let's calculate the expected code length (in bits per symbol) used by the above scheme. For large enough, we can safely assume that by the AEP. Furthermore, we know that needs at most bits to represent (theorem-1 part 2). Thus, denoting the code length by , we have where the first term corresponds to the typical sequences and the second term to everything else (not that we use the simplest possible encoding for non-typical sequences since they don't really matter in terms of their probability). Also note that we add to each of the lengths to account for the or we prefix in the scheme above. Simplifying the above, we have where represents terms bounded by for some constant when is small. Thus we can achieve code lengths arbitrary close to bits/symbol by selecting and appropriately!
- Describe the decoding algorithm for the above scheme and verify that the scheme is indeed lossless.
- What is the complexity of the encoding and decoding procedure as a function of ? Consider both the time and memory usage. Is this a practical scheme for large values of ?